Humans have reached the pinnacle of traditional computing. We have built various programming constructs to solve real-world problems. Today, we are witnessing yet another challenge on the journey to make life easier. Machine learning coupled with powerful GPUs are paving the path to solving much more significant problems.
Over the years, the development of the programming languages has evolved to accommodate faster processing and maximum functionality. As technology evolves and we enter a new era, we observe several major changes in our technological ecosystem. One of the major evolutions is upcoming of the cognitive computing.
What is cognitive computing?
Combining data analysis and an adaptive page behavior, cognitive computing is the modern day working of the computers. It is a combination of machine learning, human speech, text, audio, video, language processing, and human-computer interaction.
The main aim is to increase the efficiency of the human making decisions. In addition, it also aims to create an environment which is adaptive, expressive, self-evolving and contextual.
With the increasing demand for big data, and complexity of decision making, a logic-based solution will not be able to fulfill the requirements. With such amount of data, it is necessary to create a system that can not only deal with extremely large quantities of data but also understand human decision-making process to get accurate results. In order to create valuable information, the machine considers the four key cognitive elements, that humans do in the process of decision making.
The four key cognitive elements include:
Observation: The first and foremost element is the observation ability. This includes understanding the presence of any physical evidence. This helps develop the idea.
Interpretation: After having observed raw data, creating an understanding is essential. This guides the observer to create an outline of the entire process. An interpretation of the observed raw data helps create a framework for the entire process.
Evaluation: Once outlined, the observation turned into the hypothesis is evaluated. This step helps us understand the difference between the right and the wrong. Weighing in on all available options, we get insight on each of the available options.
Decision: After evaluating all available options, the decision-making process becomes simple. Post evaluation, the hypothesis with the best efficiency can be selected.
What is the IBM Watson AI Assistant?
The ability to follow the decision-making process traditionally used by humans differentiates Watson from any other programming system. Watson AI assistant, formerly known as Watson conversation is a smart enterprise assistant that runs through Artificial intelligence (AI) and the Internet of Things (IoT).
Building Chatbots with IBM Watson Assistant: End-to-End is a complete course to help you get started with the IBM assistant to build chatbots that enage your customers.
The IBM Watson AI assistant focuses on creating a better customer experience for enterprises and brands. It uses a variety of mediums such as multiple communication platforms, mobile devices, and robots. The tea chatbot is majorly powered using the concept of the AI Assistant.
How does Watson work and learn?
The IBM Watson AI assistant has the ability to understand unstructured data which constitutes almost 80-85% of the internet. This includes images, text, audio, video etc.
Rather than accessing a structured database, Watson holds the ability to understand human language. Watson, rather than focusing on the traditional keyword approach, understands the context of the text. Unlike speech recognition, Watson tries to understand the intent of the speaker. This enables it to learn the language, its jargons, and motive.
It further uses this to access every possible literature piece on the Internet and creates a web of information. This information is used to extract logical inferences and create answers. The entire process depends on algorithms and linguistic models. The learning process is varied and consists of several stages.
1. Corpus Creation: A very important part of the learning process is the creation of a corpus. With the help of human intervention, Watson helps gain literacy in a specific domain. This gathered knowledge is called the Corpus.
2. Content Curation: But, the creation of the corpus is a two-way street. First, it requires feeding the knowledge of the domain into the system. Now, once the data has been loaded, humans intervene to access the data and validate the contents. They remove any invalid or outdated information from the system. The process is called curation of content.
3. Ingestion: Once the data has been curated, Watson takes charge and processes the data. During pre-processing, it assigns indices and other meta-data to the information stored. This enables the efficient working of the content with ease of access. The process is known as Ingestion. The process also enables Watson to create a Knowledge graph for the stored data. The knowledge graph enables the AI assistant to give precise answers to the questions.
4. Information Interpretation: Once the data has been ingested, it is necessary to train Watson to interpret the data stored. This requires a human expert. With the help of the experts and combination of machine learning the AI, assistant gains an expertise and the ability to observe patterns.
Combining Machine learning with information
Post ingestion, interactions between Watson and Human experts in specific domains increases. To initiate the training process, the expert will feed information in the form of question-answer pairs. These pairs uploaded will help understand linguistic patterns in the domain rather than supply information and exploit answers.
Once the Q/A pairs have been fed into the system, the learning process remains ongoing. Watson will interact with humans and this interaction, closely monitored by experts is reviewed periodically. Now, the information stored within the Watson is also updated. Combining the two processes together gives us an ever-learning process for the Watson AI Assistant. It is now in a position to answer complex questions and queries based on what it has learned.
Key Features of Watson AI
Watson AI assistant by IBM has been revolutionary. It serves various clients but there are certain features that make it stand out. Let us look at some of these key features.
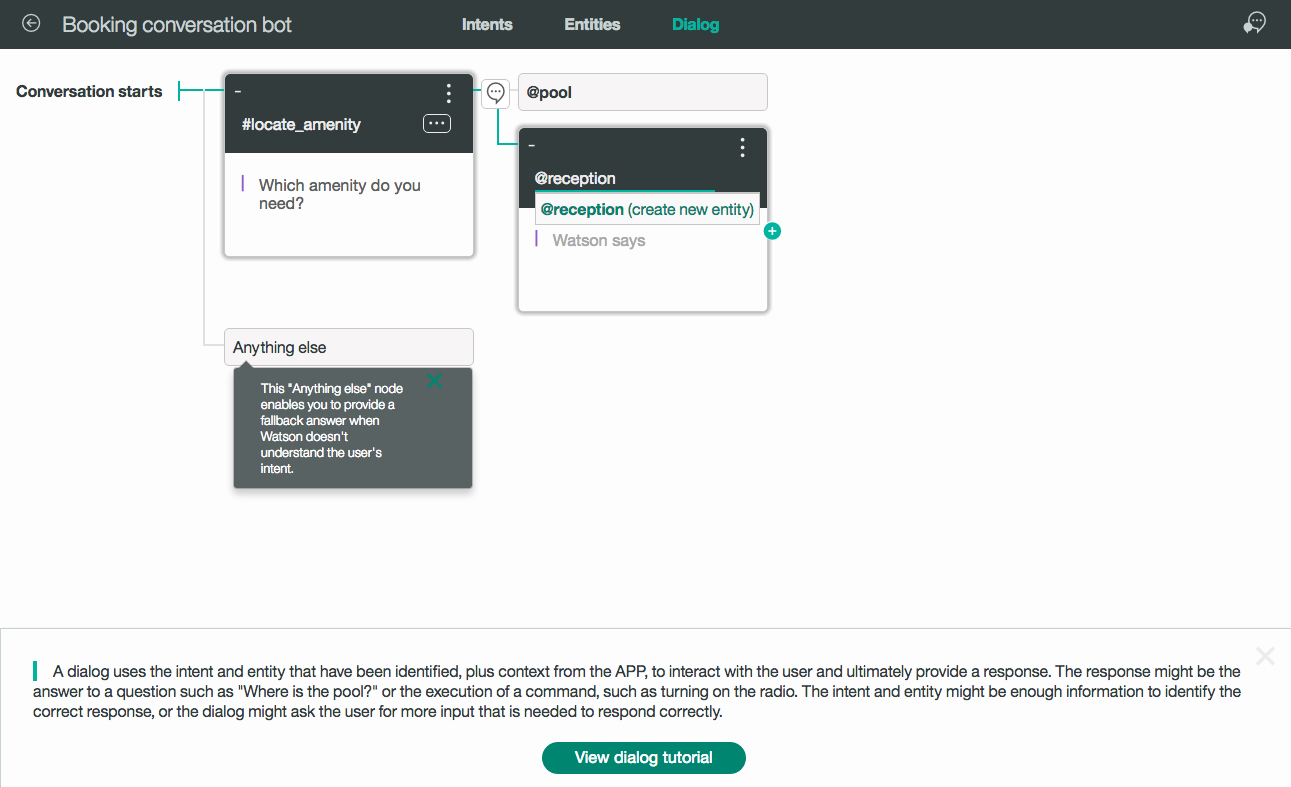
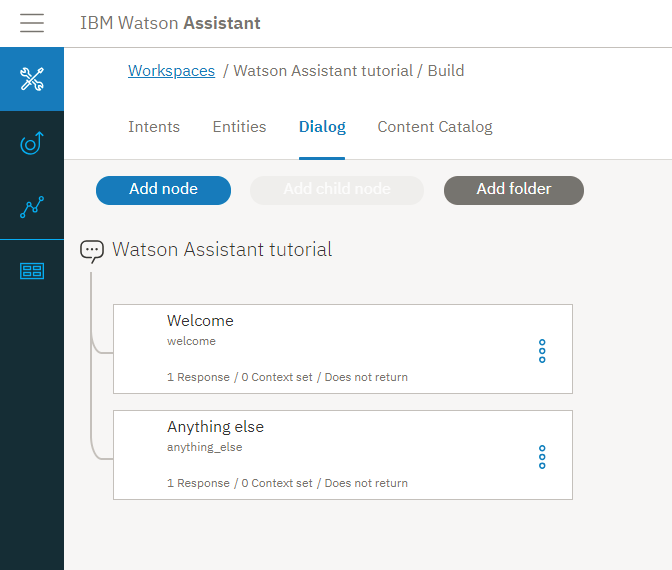
Friendly UI: With the complexities of its working, one might be under the impression that Watson is complex to operate. But, it offers the users a simple and easy-to-use UI. It offers a tree view and enables the user to save dialog nodes in the folders.
Domain-based content: Watson offers the users a plethora of pre-built content for various domains. This not only saves the users on time and effort but also simplifies the process of building from scratch. The users can simply browse the catalog and start working.
Data Privacy: With such important data at hand, IBM offers users control over their data. The data collected and generated can be used for improving the model by the system. So, during training, the users get control over the usage and privacy of the data.
Analytics: The user interaction with Watson is constantly being recorded. Hence the users can understand the patterns formed and the quality of the interactions. This helps the user train the model according to the needs and requirements.
Channel integration: The Watson AI assistant in an attempt to offer smart user experience, can be embedded with various channels to give a safe and secure interaction. This is built for multiple industries and can be utilized irrespective of the field or scope of work.
Eradicating the bias with Watson AI
Recently, Joy Buolamwini, an MIT researcher probed into facial recognition technology by Microsoft and IBM, only to find out that the technology created a bias. Their facial recognition worked better on fair-skinned men than those with a dark skin tone. The companies have since claimed to improve the accuracy. But, does this mitigate the problem?
The answer isn’t quite right. There have been concerns over such matters. The technology tends to discriminate against certain groups of color and gender. Watson AI, launched by the tech giant IBM focuses on putting an end to these unintentional biases. The problem is being linked to the data sets which are used in machine learning. These datasets fall short of images being used and their diversity.
Buolamwini believes that lack of diversity in the team causes the bias to spread into the algorithm. IBM has now taken up the daunting task of curating diverse content to eradicate this AI error which impacts millions of people. According to the company, Watson AI is the solution to the problem.
Conclusion
The IBM powered Watson AI Assistant is a tool of the future with an aim to deliver a world-class experience to its users. It focuses on customer interactions with each interaction being better than the last. It also enables enterprises to generate insights and find out the shortcomings. And the most important part is the accessibility of the system over the cloud.
If this has peeked your interest, then get started with the Watson Assistant.
Here are some IBM AI code patterns to help you to get started quickly.
