
Web Scraping is nothing but extracting a large amount of data from the internet and storing it in your local drive. Here you will be extracting the data directly from the source. With the help of scraping, now you will be able to download and store data which you previously could not .
Is it legal ?
Yes, it is, provided the data is in public domain and doesn’t have any copyright.
How is Web-scraping with Python useful?
Web scraping with Python is generally used to gather huge amounts of data and process it according to one’s needs. For example, you might want to get the data (Cost, reviews, etc) a particular product from various sellers on amazon, and then compare them to decide which one you want to go for. In such cases, it’s easier to scrape the data.
(Note – Amazon does not allow this and your IP will be banned , so you will have to use a proxy)
How to perform Web-scraping ?
Here, you will learn how to use web scraping with Python to solve a particular type of problem.
Every year, lakhs of students write public exams and at the time of results, I have seen my teachers struggle to try to extract all their students’ data from the result website. It’s a tedious job of manually entering each student’s ID and copying their sore to an excel sheet. So we are going to solve this issue by python code and selenium API to extract the required data and save it in an excel sheet.
1. Prerequisites
Make sure to install the following packages :
- requests – Package is used to get the HTML of the website you are requested for scraping.
- lxml – This library is used to parse the data type into python readable data type.
- BS4– This library is used to analyze the extracted web page
- selenium -To connect with the web browser and perform the task required task.
- openpyxl – To work with excel workbooks.
- argparse – To take the arguments from the command line
To install it , just open command prompt and type:
pip install requests pip install lxml pip install BS4 pip install selenium pip install openpyxl pip install argparse
After installation , download the web browser drivers. Following are the links for different web browsers, choose the appropriate one.
(Note – always install the version corresponding to the version of your web-browser )
2. Inspecting
For the problem we’re trying to solve, we have a web page (image 1) where we need to enter student’s registration numbers and press enter to see the results. The results will be displayed as seen in image 2 .
To automate this process, we need the HTML tag for the input box and tags for the data we need from the Result pagem . Tags such as students name, subject, marks,etc should be extracted.


The following are the steps to identity the required Tags:
- To check for the DOM, right click on the input box where you enter the registration number and click on inspect element . In the elements tab when you place your cursor on: id = “reg” , it highlights the input box where you can enter the registration number. Now we know that the key/tag is “reg”, we will be using this in our code to input the students registration number.
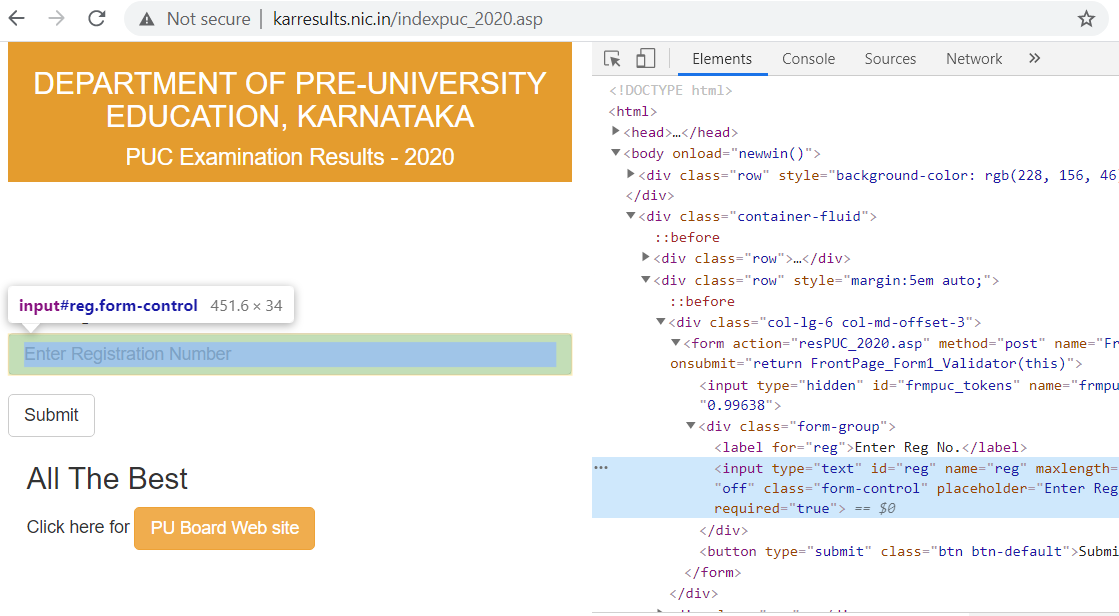
- Similarly in the results page ,we right click on the Student name and select inspect element . Here the cursor is moved on the student’s name , the tag “td” is highlighted.
As you explore, we see that all the data we need are under the “td” tag. We can now use this tag to extract our data.

Conclusion
So, this was our introduction to extracting the data from the website and the first part to web scraping with python. In the next part, we will get into the programming part of it, you can find the link to the second part below.
Link to Part 2: Python Web Scraping
If you are interested in python programming, you can check our top python course guide to help you navigate through the python programming world.



