What are Wordnet, Hyponyms, and synonyms?
Wordnet is a large collection of words and vocabulary from the English language that are related to each other and are grouped in some way. That’s the reason WordNet is also called a lexical database.
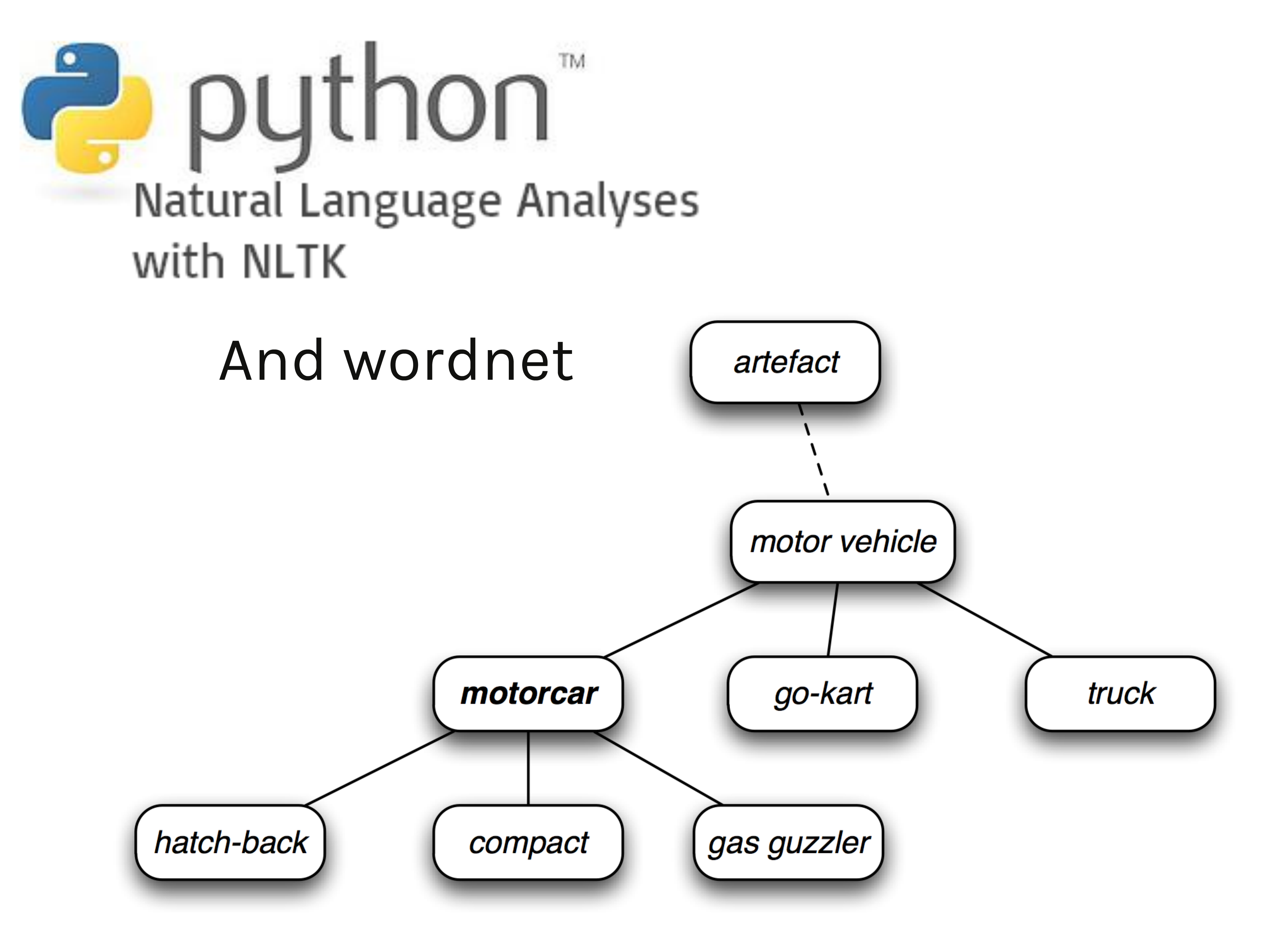
WordNet groups nouns, adjectives, verbs which are similar and calls them synsets or synonyms. A group of synsets might belong to some other synset. For example, the synsets “Brick” and “concrete” belong to the synset “Construction Materials” or the synset “Brick” also belongs to another synset called “brickwork “. In the example given, brick and concrete are called hyponyms of synset construction materials and also the synsets construction material and brickwork are called synonyms.
You can imagine wordnet as a tree, where synonyms are nodes on the same level and hyponyms are nodes lower than the current node.
What is Python nltk ?
Natural Language Toolkit (NLTK) is a python library to process human language. Not only does it have various features to help in natural language processing, it also comes with a lot of data and corpus that can be used. Wordnet is one such corpus provided by nltk data.
How to install nltk and Wordnet ?
To install nltk on Linux and Mac, just run the following command :
sudo pip install nltk
For full installation details and installation on other platforms visit their official installation page.
Once nltk is downloaded, you can download wordnet using the nltk data interface. Follow the instructions given here.
How do you find all the synonyms and hyponyms of a given word ?
We can use the downloaded data along with nltk API to fetch the synonyms of a given word directly. To fetch all the hyponyms of a word, we would have to recursively navigate to each node and its synonyms in the wordnet hierarchy. Here is a python script to do that.
-
Get all synonyms or Thesaurus for a given word
from nltk.corpus import wordnet as wn input_word = raw_input("Enter word to get different meanings: ") for i,j in enumerate(wn.synsets(input_word)): print "Meaning",i, "NLTK ID:", j.name() print "Definition:",j.definition() print
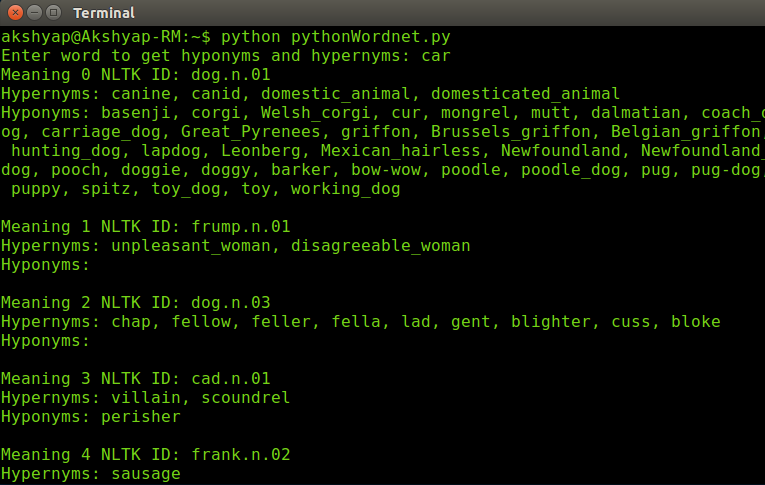
Following example finds the synoyms/ synsets for the word car:

-
Get all the hyponyms and hypernyms for a given word
from nltk.corpus import wordnet as wn from itertools import chain input_word = raw_input("Enter word to get hyponyms and hypernyms: ") for i,j in enumerate(wn.synsets('dog')): print "Meaning",i, "NLTK ID:", j.name() print "Hypernyms:", ", ".join(list(chain(*[l.lemma_names() for l in j.hypernyms()]))) print "Hyponyms:", ", ".join(list(chain(*[l.lemma_names() for l in j.hyponyms()]))) printhypernyms are nothing but synsets above a given word. Getting all the hypo and hypernyms are also called ontology of a word. In the following example, the ontology for the word car is extracted.

-
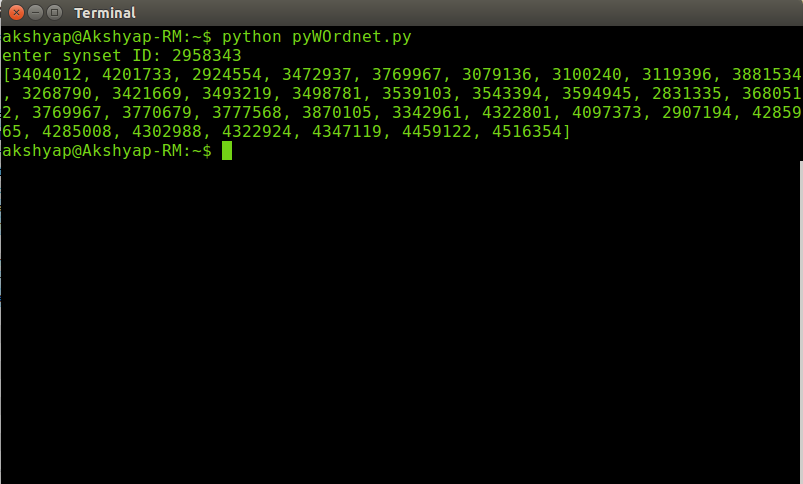
Get all Hyponyms with synsetID
each synset has an Id which is nothing but the offset of that particular word in the list of all words. If you know the Id of a synset and want to find out the id of all the hyponyms instead of meanings and definitions, you can do this:
from nltk.corpus import wordnet as wn X = [] id = int(raw_input("enter synset ID: ")) wr = wn._synset_from_pos_and_offset('n',id) def traverse(wr): if(len(wr.hyponyms()) ==0): X.append(wr.offset()) else: list_hypo = wr.hyponyms() for each_hypo in list_hypo: traverse(each_hypo) traverse(wr) print X

Source : StackOverflow