
Thanks to Google, we can now just download the inception V3 pre-trained model and setup our image classifier. We don’t have to spend a huge amount of time training this model from scratch. The pre-trained model can classify 1000 different objects and we can also add more classes or categories to it. The time it takes to retrain Tensorflow Inception model is much lesser than the time taken to train it from scratch.
The reason why we don’t train for the new models from scratch is because it can take many days or a few weeks to train on lower hardware specifications. When we retrain Tensorflow Inception model, we can do it within a few hours or a day. More the number of classes, higher will be the retraining time. To continue with this tutorial, it will help if you are familiar with some of Tensorflow’s concepts and working. If you aren’t, then you can read more in this Simple guide to Tensorflow’s concepts and jargons.
Also, if you haven’t already, check out the tutorial on setting up tensorflow image classifier with a pre-trained model. This is for beginners to test what a classifier built with deep learning can do.
How does the Retraining work?
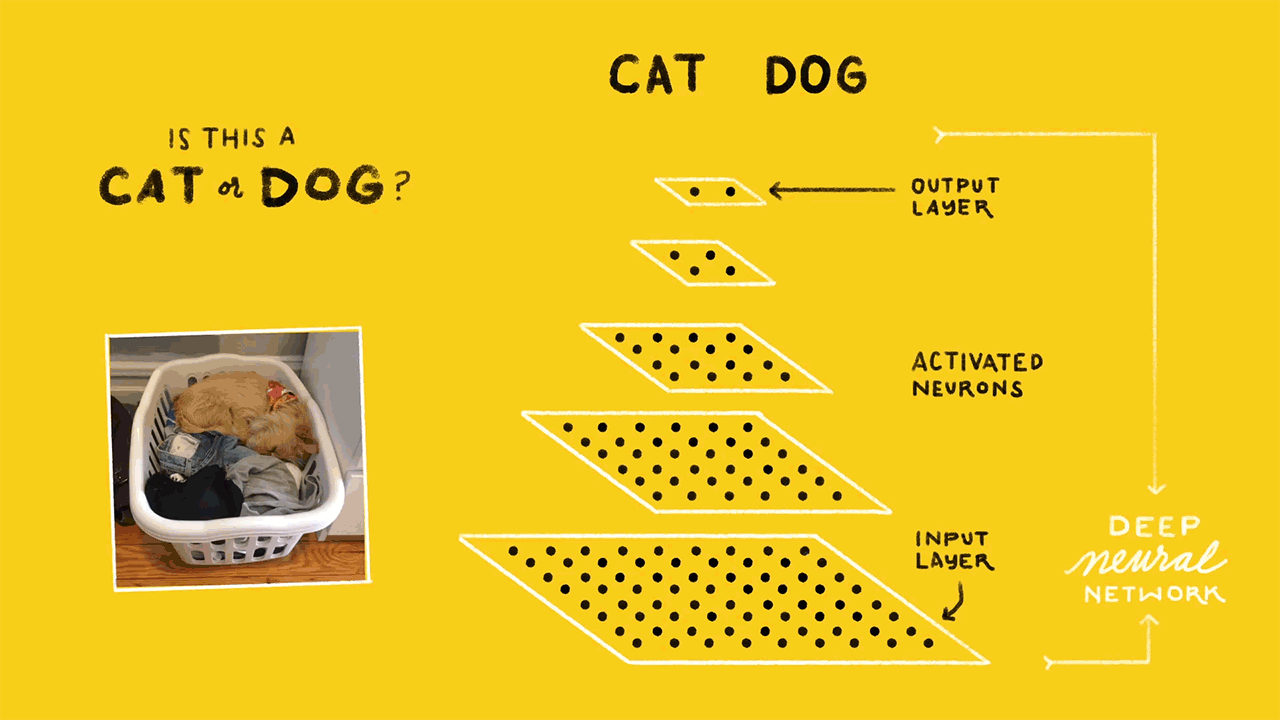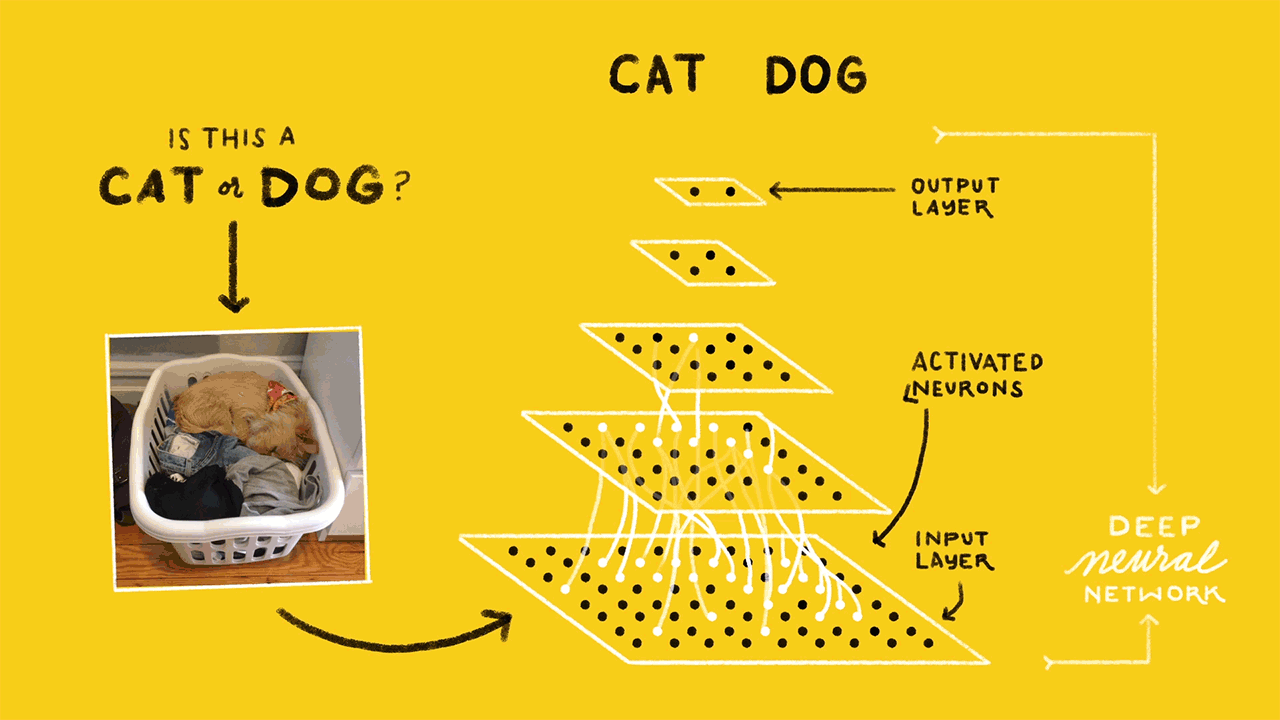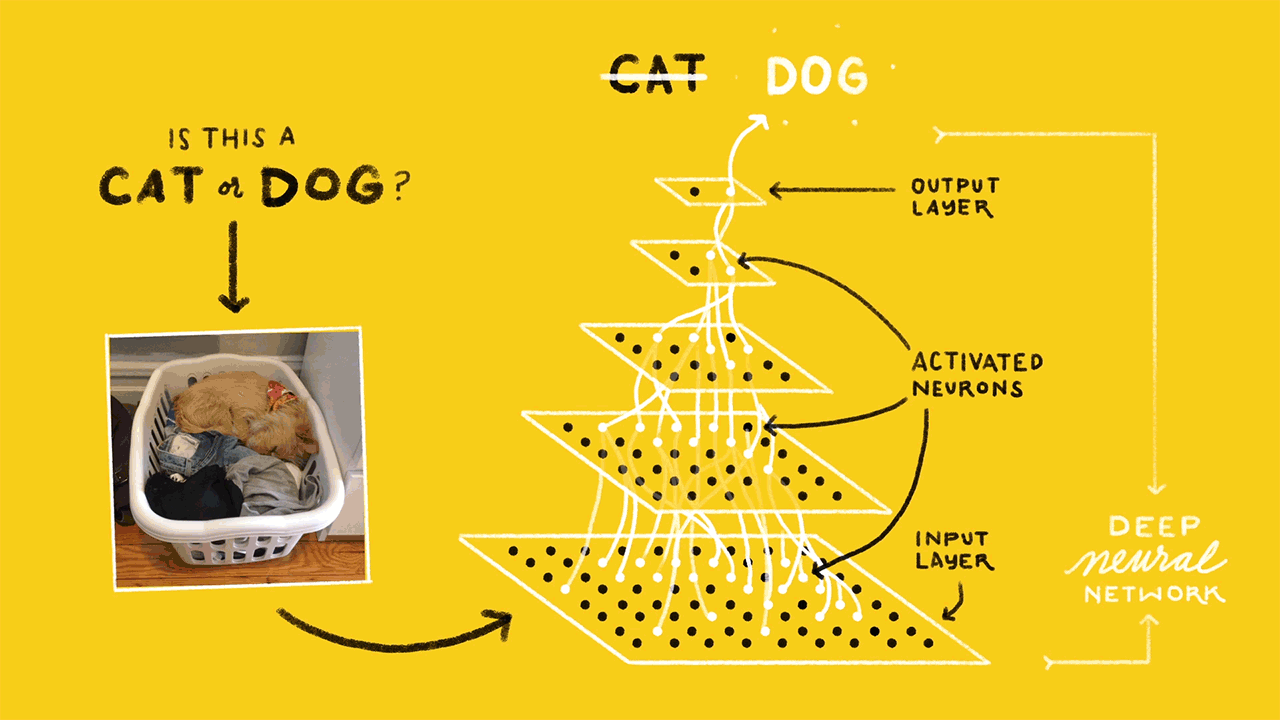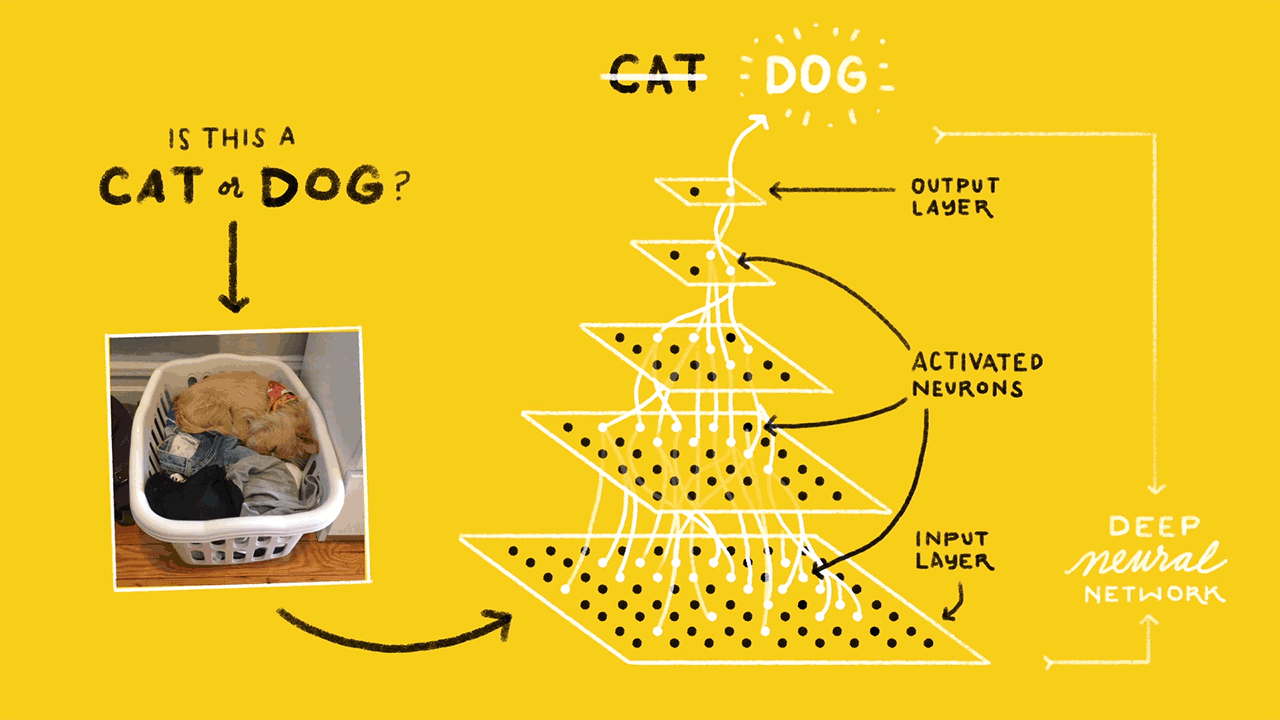
By now, you know that the retraining is a quick process on a machine with a decent GPU. To understand why it is quick, you need to know the concepts of Tensorflow Bottlenecks. The last but one layer of the neural network is trained to give out different values based on the image that it gets. This layer has enough summarized information to provide the next layer which does the actual classification task. This last but one layer is called the bottleneck.
Tensorflow computes all the bottleneck values as the first step in training. The bottleneck values are then stored as they will be required for each iteration of training. The computation of these values is faster because tensorflow takes the help of existing pre-trained model to assist it with the process. Be default 4000 iterations of training will be performed. This can be varied depending on the accuracy required. Computation of bottleneck values takes the maximum amount of time in a retraining process.
Step1: Download the pre-trained model and the required scripts.
I have combined all the required files into a git repository. Download it by using the following command and navigate in to that folder.
git clone https://github.com/akshaypai/tfClassifier cd tfClassifier
This folder contains the scripts required to retrain the classifier and also the pre-trained model which we will be using.
Step2: Setup the image folder
This step involves setting up the folder structure so that tensorflow can pick up the classes easily. Let’s assume that you want to train 5 new flower types, say “roses”, “tulips”, “dandelions”, “mayflower”, and “marigold”. To create the folder structure,
- Create one folder for each flower type. The name of the folder will be the name of the class ( in this case, that particular flower).
- Add all the images of the flowers into its respective folders. Eg; all images of roses go into the “roses” folder.
- Add all the folders into another parent folder, say, “flowers”.
At the end of this exercise, you will have the following structure:
~/flowers ~/flowers/roses/img1.jpg ~/flowers/roses/img2.jpg ... ~/flowers/tulips/tulips_img1.jpg ~/flowers/tulips/tulips_img2.jpg ~/flowers/tulips/tulips_img3.jpg ...
This will repeat for all the folders. The folder structure is now ready.
Ad: Don’t miss – Python for Data Science and Machine Learning Bootcamp![]()
Step 3: Running the re-training script
Use the following command to run the script.
python retrain.py --model_dir ./inception --image_dir ~/flowers --output_graph ./output --how_many_training_steps 500
command line arguments:
- –model_dir – This parameter gives the location of the pre-trained model. the pre-trained model is stored under the inception folder of the git repository.
- –image_dir – Path of the image folder which was created in step 2
- –output_graph – The location to store the newly trained graph.
- –how_many_training_steps – Training steps indicate the number iterations to perform. By default, this is 4000. Finding the right number is a trial and error process and once you find the best model, you can start using that.
Your new model can perform better. Thus, use other parameters to improve accuracy.
- random_crop – Random cropping allows you to focus on the main part of the image.
- Random_scale – This is similar to cropping but it randomly scales up the image size.
- flip_left_right – Flipping is rotating the image horizontally and with this feature, a flip can be induced randomly in the training images.
The size of validation and test set in percentages and in numbers can be controlled. Distortion includes random brightness as well. Distortions are induced to take into account the various anomalies that occur during the real-time detection phase. The type of distortion that suits you is dependent on the type and classes of images that you are using. This makes the parameter selection and tuning a trial and error exercise.
Update 1: Added code to test the retrained model
Once you have the trained model, you will have two files as output. First is the “ouput.pb” file and the second one is the “labels.txt” file. To test the model, you can find a new script in the git Repository named “retrain_model_classifier.py” . To test the model follow the procedure below.
- Make sure the retrain_model_classifier.py is in the same folder as the retrained model and labels file.
- Run the following command.
python retrain_model_classifier.py <image_path> #following is an example of classifying an image present in Pictures directory:&nbsp; python retrain_model_classifier.py /home/akshay/Pictures/test_image_flower.jpg #following is an example output """ rose ( score=0.78) tulips( score=0.14) others( score =0.02) """
Note:
- The output will be the probability values of each class with the highest one being the first. In the example below, The model says that it is 78% confident that the image belongs to the “rose” class. Thus the classified result will be “rose”.
Conclusion
So, this is how you retrain Tensorflow Inception model on Ubuntu. The accuracy of the model is printed at the very end of the training process. Once you have the model, you can use it for the classification process.
Remember that the older classes will no longer be available. You will be able to classify only on those classes on which you have retained.
If you are interested to learn machine learning and python in depth, then investing in Python for Data Science and Machine Learning Bootcamp![]() would give you an amazing platform to learn and grow.
would give you an amazing platform to learn and grow.
Subscribe to my blog below for free tutorials on Tensorflow and machine learning delivered straight to your inbox.



Nice write up. Can you please add the steps on how to do the validation of the trained model?
Thanks,
Rupam Roy
I am getting the below error when trying to o some validation tests :
KeyError: “The name ‘softmax:0’ refers to a Tensor which does not exist. The operation, ‘softmax’, does not exist in the graph.
any idea what is causing this?
Hi,
So that error is occurring because this new model which has been trained contains a softmax later in the end that helps in classification. what script are you using for validating the trained models ?
I have the same issue. After I use the retrain.py to have the new pb and pbtxt file. I use the classifier.py to validate the image file. I got the error: “The name ‘softmax:0’ refers to a Tensor which does not exist. The operation, ‘softmax’, does not exist in the graph.” . And I do get the “Converted 2 variables to const ops.” prompt.
can you show me the full command that you are using to run the classifier.py script?
The full command is: “python3 classifier.py –image_file ./image/test.jpg”
Somehow I am not getting this error. I have added another file to the git repo “retrain_new.py”. this new script has been updated to run with the newer version of tensorflow.
Another thing is that the classifier.py should not be used to test the new model that you have retrained. This is only to set up a simple imagenet classifier and run it. What you would have to do is create a tensorflow session by loading your new model and getting the predictions in a to session like : top_k = predictions[0].argsort()[-len(predictions[0]):][::-1]
I will upload a full script by this weekend.
Awesome! The latest version is worked. Thanks for your quickly reply and update.
You’re welcome
” python3 retrain.py –model_dir ./inception –image_dir ../image –input_binary=true” . After get the “Converted 2 variables to const ops.” , I copy the /tmp/output_graph.pb and /tmp/output_labes to ./inception as classify_image_graph_def.pb and imagenet_2012_challenge_label_map_proto.pbtxt. Then run the classifier.py, and get the error.
Image directory ‘~\fabrics’ not found.
Traceback (most recent call last):
File “retrain.py”, line 970, in
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
File “C:\Users\itagi\Anaconda3\lib\site-packages\tensorflow\python\platform\app.py”, line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File “retrain.py”, line 716, in main
class_count = len(image_lists.keys())
AttributeError: ‘NoneType’ object has no attribute ‘keys’
I am getting the following error when running on windows 10
the structure “~/fabrics” is used for Linux. Could you try giving the full path of the folder and running it again?
It worked .Thank you very much.
How do we provide a single image and know which class it belongs to.
You’re welcome. As of now that script to test the classifier, I haven’t uploaded. I’ll be uploading it by this weekend and you can use that .
Until then, you can try to create a the session and use the prediction on the model.
There is another script “classifier.py” in the GitHub repo but that will only work with imagenet model and not the retrained model.
Which model is best for image classifying ? Alexnet or Inceptionv3
Definitely Inception V3. It’s newer and has better accuracy fro image classification. As of now there is Resnet V2 which is better performing than inception V3. But you would have to use the new TF slim to work with it.
How to classify a single image on two categories?Like example i want to categorize a flower as both rose and red ,or rose and white rose.
The way classifier works is that gives as result the class which has the highest probability. What you want to achieve is a bit tricky. I can think of three ways to do it.
1. you can create an exhaustive set of classes in case there aren’t many. This way, you will be creating one class for “red rose”, “white rose”, “white tulips”, “pink tulips”, etc and training a classifier. I feel this would be the easiest but it isn’t scalable if there are a lot of classes and combinations.
2. Another simple way would be to have separate classes for each flower and its variation. That is one classifier with classes like “Rose”, “tulip”, “red rose”, “white rose”, “pink tulip”, etc. Then, when you perform the classification and picking only the result with the highest probability, you can get all the probability value and write a custom logic which picks the one with the highest probability among flower classes (rose, tulips, etc) and among its corresponding colors, pick the highest probability among ( red rose, white rose, etc)
3. another way would be to have multiple classifiers in place. This is a more cleaner solution. One classifier for roses, tulips, etc and another one to identify the colors, red, white, pink etc.
Do you have a video in you tube which explains the retrain.py code briefly.Actually i am new to deep learning .Or else can you give a short summary about how the code works .Can you also tell how it takes the datasets for training and testing in retrain.py and prediction of training accuracy and those parameters.
Thank you
Hi,
So there isn’t a video yet. But I am planning to create one and hopefully upload it soon. I will mail you once the video is up so that you can learn via that. Giving a summary of the code requires a lot of time as many things are involved in that. Due to that, I would have to write another blog post and as of now, that would take a long time. But I will create and upload a video for sure.
Hello there!You have said to upload a script for classifier .If you have uploaded can you give me the link.Thank you!
Hi, I Have updated the blog post. See section “Update 1: Added code to test the retrained model” to know how you can test it. I have added the code to Github repo as well.
C:\Users\i\tfClassifier>python retrain_model_classifier.py D:\CSDAML\Project_fabric\Dataset\img01.jpg
Traceback (most recent call last):
File “retrain_model_classifier.py”, line 12, in
in tf.gfile.GFile(“./labels.txt”)]
File “retrain_model_classifier.py”, line 11, in
label_lines = [line.rstrip() for line
File “C:\Users\i\Anaconda3\lib\site-packages\tensorflow\python\lib\io\file_io.py”, line 170, in __next__
return self.next()
File “C:\Users\\Anaconda3\lib\site-packages\tensorflow\python\lib\io\file_io.py”, line 164, in next
retval = self.readline()
File “C:\Users\Anaconda3\lib\site-packages\tensorflow\python\lib\io\file_io.py”, line 133, in readline
self._preread_check()
File “C:\Users\Anaconda3\lib\site-packages\tensorflow\python\lib\io\file_io.py”, line 75, in _preread_check
compat.as_bytes(self.__name), 1024 * 512, status)
File “C:\Users\Anaconda3\lib\contextlib.py”, line 66, in __exit__
next(self.gen)
File “C:\Users\Anaconda3\lib\site-packages\tensorflow\python\framework\errors_impl.py”, line 466, in raise_exception_on_not_ok_status
pywrap_tensorflow.TF_GetCode(status))
tensorflow.python.framework.errors_impl.NotFoundError: NewRandomAccessFile failed to Create/Open: ./labels.txt : The system cannot find the file specified.
i am getting this error when i run the retrain classifier in windows
That is because the path of the file given isn’t according to Windows standard. In the script “retrain_model_classifier.py”, you have to change “./lables.txt” to the full path of where that file is present.
Do the same for the “./output.pb” as well. Replace that by the full path of the file in Windows. It will then work.
Where can I find these two files ? Are they in your tfClassifier directory or in Anaconda libraries ? Because I could not find labels.txt file in your directory.
These two files are the output of your retraining script. When your the retrain.py, labels.txt and output.pb should be generated. It will be stored in the same file as the retrain.py directory. Once you have those two, you can run the script for testing you’re model.
When I run this retrain.py code, I got output as total test accuracy in command prompt window but these two file have not generated in my directory though I have file called output but it is not output.pb type . Is this because I am working on windows ?
If you got that in command prompt, the file would have been stored. You can check the code in retrain.py as to where the files are being stored. You can also change the path so that you know where exactly it will be stored
Hi,
thanks for this tutorial ! i managed to get it working but in my labels.txt i am not getting the node names.
instead of:
n00004475 organism, being
n00005787 benthos
i am getting just:
tulips
roses
and when i run test the classifiers, it returns me tulips when i give it roses and vice versa,
could this be due to the missing node names ?
Hey Jordan. The reason why you might be getting roses and tulips is because the folder names in your image directory might be named roses and tulips instead of organism, being, etc.
The classification being wrong might be because the model is not trained for enough number of steps. For that you can increase the –how_many_training_steps 500 to say around 4000 while running the command. This way you might get better accuracy
I get this error when I try to retrain my own classifier on Ubuntu 16.04:
Traceback (most recent call last):
File “retrain.py”, line 967, in
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
File “/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py”, line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File “retrain.py”, line 750, in main
train_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + ‘/train’, sess.graph)
AttributeError: ‘module’ object has no attribute ‘SummaryWriter’
Any idea about this problem? Thank you
Hi, I think that your Tensorflow version is older.
You can perform “pip install tensorflow –upgrade” for python 2 or use “pip3 install tensorflow –upgrade” for python3 to upgrade to latest tensorflow version and try again
Thanks for the answer. This didn’t work but I solved the problem by changing:
train_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + ‘/train’, sess.graph)
validation_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + ‘/validation’)
by
train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + ‘/train’, sess.graph)
validation_writer = tf.summary.FileWriter(FLAGS.summaries_dir + ‘/validation’)
Awesome ..
./labels.txt has not been created.
It should be created. This code is working perfectly on both windows and linux. Please make sure that you have given the path correctly while starting the script.
WHICH PATH
By default, your labels.txt is stored in /tmp/output_labels.txt . Now if you aren’t on ubuntu, then while running the script, you can give another option ” –output_labels ”
okay thank you very much.Its working now.
You’re welcome
Hi I get this error when I try to retrain
Traceback (most recent call last):
File “retrain_new.py”, line 1019, in
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
File “/PythonCode/tfLabs/lib/python3.5/site-packages/tensorflow/python/platform/app.py”, line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File “retrain_new.py”, line 872, in main
f.write(output_graph_def.SerializeToString())
File “/PythonCode/tfLabs/lib/python3.5/site-packages/tensorflow/python/lib/io/file_io.py”, line 101, in write
self._prewrite_check()
File “/PythonCode/tfLabs/lib/python3.5/site-packages/tensorflow/python/lib/io/file_io.py”, line 87, in _prewrite_check
compat.as_bytes(self.__name), compat.as_bytes(self.__mode), status)
File “/usr/lib64/python3.5/contextlib.py”, line 66, in __exit__
next(self.gen)
File “/PythonCode/tfLabs/lib/python3.5/site-packages/tensorflow/python/framework/errors_impl.py”, line 466, in raise_exception_on_not_ok_status
pywrap_tensorflow.TF_GetCode(status))
tensorflow.python.framework.errors_impl.FailedPreconditionError: ./output_dir/
looks like it is not able to create the output directory
hi~ thank you very much first.
I have a question, how to distribute your program? I want it work on many GPU or computers.
Hi wang,
I am glad you found the article useful. To answer your question on using multiple GPUs, my code does not do it out of the box, a re-write of the application is required to distribute the work to the other GPUs. I found the following articles that can help you further: https://www.tensorflow.org/tutorials/using_gpu#logging_device_placement, https://blog.rescale.com/deep-learning-with-multiple-gpus-on-rescale-tensorflow/
Traceback (most recent call last):
File “retrain_model_classifier.py”, line 12, in
in tf.gfile.GFile(“./labels.txt”)]
File “/usr/local/lib/python2.7/dist-packages/tensorflow/python/lib/io/file_io.py”, line 164, in next
retval = self.readline()
File “/usr/local/lib/python2.7/dist-packages/tensorflow/python/lib/io/file_io.py”, line 133, in readline
self._preread_check()
File “/usr/local/lib/python2.7/dist-packages/tensorflow/python/lib/io/file_io.py”, line 75, in _preread_check
compat.as_bytes(self.__name), 1024 * 512, status)
File “/usr/lib/python2.7/contextlib.py”, line 24, in __exit__
self.gen.next()
File “/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/errors_impl.py”, line 466, in raise_exception_on_not_ok_status
pywrap_tensorflow.TF_GetCode(status))
tensorflow.python.framework.errors_impl.NotFoundError: ./labels.txt
Hi! When I run retrain model file it errors How Can I fix it? Thank you.
Looks like your labels.txt file is not present in the home directory. You might want to change the location of labels.txt to home folder or change the path of labels.txt in the retrain_model_classifier.py file in line 12.
with –output_graph when I run file retrain.py I can’t find output_graph.pb file in tmp directory. How I can run file retrain_model without knowing path of output_graph file? Can you help me to fix it? I run it on raspberry pi 3. Thank you so much
when you use the –output_graph, option, you should be specifying the path of where you want the output_graph.pb file to be. if you want the file to be in the tmp directory, then you have to not give the “–output_graph” option.
I get this error when I retrain
Traceback (most recent call last):
File “/anaconda/lib/python3.5/site-packages/tensorflow/python/client/session.py”, line 1068, in _run
allow_operation=False)
File “/anaconda/lib/python3.5/site-packages/tensorflow/python/framework/ops.py”, line 2708, in as_graph_element
return self._as_graph_element_locked(obj, allow_tensor, allow_operation)
File “/anaconda/lib/python3.5/site-packages/tensorflow/python/framework/ops.py”, line 2750, in _as_graph_element_locked
“graph.” % (repr(name), repr(op_name)))
KeyError: “The name ‘DecodeJpeg/contents:0’ refers to a Tensor which does not exist. The operation, ‘DecodeJpeg/contents’, does not exist in the graph.”
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “retrain_model_classifier.py”, line 25, in
{‘DecodeJpeg/contents:0’: image_data})
File “/anaconda/lib/python3.5/site-packages/tensorflow/python/client/session.py”, line 895, in run
run_metadata_ptr)
File “/anaconda/lib/python3.5/site-packages/tensorflow/python/client/session.py”, line 1071, in _run
+ e.args[0])
TypeError: Cannot interpret feed_dict key as Tensor: The name ‘DecodeJpeg/contents:0’ refers to a Tensor which does not exist. The operation, ‘DecodeJpeg/contents’, does not exist in the graph.
kangbanjundeMBP:image_classification frank$ python retrain_model_classifier.py /Users/apple/Desktop/church.jpg –restore_op_name=deploy/save/restore_all –filename_tensor_name=deploy/save/Const:0
can anybody help me?
my tensorflow version is 1.3.0
Accuracy, I get this error when I “using retrain model”
by following command
python retrain_model_classifier.py /Users/apple/Desktop/church.jpg
Hello, what if I have retrained model, but later I want train it more. Is it possibble to not start from the beginnig again? Thank you for answer.
There are two ways you can go about this. Firstly, you can modify the code to keep saving models at various intervals. For example, store a model every 5000 steps if you are running it for 30,000 steps.
Secondly, thing you can try is to stop the training and when you want to continue, start it again. I had done this a long time back and the training surprisingly resumed instead of starting from the beginning. I am not sure if that is still possible as of now.
Hi, I keep on getting this error everytime I run the training script.
tensorflow.python.framework.errors_impl.UnknownError: Failed to create a NewWriteableFile: C:\Users\lander jr\djangoprojects\TenStoreFlow\External : Access is denied.
; Input/output error
Nevermind, I got it. Thanks!
Hello. I’ve already been successful retraining once, but the moment I do it again it overwrites the previous labels.txt that is produced. How do I just add it to the existing model that I have retrained?
I don’t think that is possible. While retraining to add a new class, you will have to start retraining from scratch with all the classes in place.
Hi, after re training. How do I add it to the pre trained model in the inception folder? Also, I’m having trouble trying to re-train again because it always overwrites the previously trained model.
Pre-trained models will be overwritten and not appended to the existing model. You would have to store it separately and start re-training again.
hi I have an error, this is what I’ve typed:
python retrain.py –model_dir ./inception –image_dir php –output_graph ./output –how_many_training_steps 100
and this is the result:
Looking for images in ‘php100’
Looking for images in ‘php1000’
Looking for images in ‘php20’
Looking for images in ‘php200’
Looking for images in ‘php50’
Looking for images in ‘php500’
100 bottleneck files created.
2017-11-10 16:13:09.343997: Step 0: Train accuracy = 73.0%
2017-11-10 16:13:09.344497: Step 0: Cross entropy = 1.729340
CRITICAL:tensorflow:Label php100 has no images in the category validation.
Traceback (most recent call last):
File “retrain.py”, line 967, in
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
File “C:\Users\qwerty\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\platform\app.py”, line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File “retrain.py”, line 794, in main
bottleneck_tensor))
File “retrain.py”, line 437, in get_random_cached_bottlenecks
bottleneck_tensor)
File “retrain.py”, line 345, in get_or_create_bottleneck
bottleneck_dir, category)
File “retrain.py”, line 231, in get_bottleneck_path
category) + ‘.txt’
File “retrain.py”, line 207, in get_image_path
mod_index = index % len(category_list)
ZeroDivisionError: integer division or modulo by zero
by the way I’m only using a small amount of datasets per folder(<20)
I’ve tried to write the path of the folder but it stops on the last step
2017-11-10 16:41:19.392994: Step 99: Train accuracy = 99.0%
2017-11-10 16:41:19.394019: Step 99: Cross entropy = 0.376532
2017-11-10 16:41:19.676990: Step 99: Validation accuracy = 70.0%
CRITICAL:tensorflow:Label php500 has no images in the category testing.
Traceback (most recent call last):
File “retrain.py”, line 967, in
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
File “C:\Users\qwerty\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\platform\app.py”, line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File “retrain.py”, line 810, in main
bottleneck_tensor)
File “retrain.py”, line 437, in get_random_cached_bottlenecks
bottleneck_tensor)
File “retrain.py”, line 345, in get_or_create_bottleneck
bottleneck_dir, category)
File “retrain.py”, line 231, in get_bottleneck_path
category) + ‘.txt’
File “retrain.py”, line 207, in get_image_path
mod_index = index % len(category_list)
ZeroDivisionError: integer division or modulo by zero
Not a date count issue, I’ve tested on Ubantu GPU, it works smoothly.
But same data set running on CentOS, will occur this error.
can you tell me what error you are getting?
The Problem I feel is caused due to a lack of good amount of training data. So, there are no images present for testing and when the test phase begins, you might have got this error.
try to increase the data count to say around 100 per class and see if this error persists.
How do I configure retrain_model_classifier.py to test all the images in a directory and return me the overall accuracy of the test? for example: 50% 50/100
I am getting the following error when I try to do the retrain_model_classifier (NOTE the last line):
Traceback (most recent call last):
File “retrain_model_classifier.py”, line 22, in
softmax_tensor = sess.graph.get_tensor_by_name(‘final_result:0’)
File “/home/ubuntu/anaconda3/envs/tensorflow_p27/lib/python2.7/site-packages/tensorflow/python/framework/ops.py”, line 2880, in get_tensor_by_name
return self.as_graph_element(name, allow_tensor=True, allow_operation=False)
File “/home/ubuntu/anaconda3/envs/tensorflow_p27/lib/python2.7/site-packages/tensorflow/python/framework/ops.py”, line 2708, in as_graph_element
return self._as_graph_element_locked(obj, allow_tensor, allow_operation)
File “/home/ubuntu/anaconda3/envs/tensorflow_p27/lib/python2.7/site-packages/tensorflow/python/framework/ops.py”, line 2750, in _as_graph_element_locked
“graph.” % (repr(name), repr(op_name)))
KeyError: “The name ‘final_result:0’ refers to a Tensor which does not exist. The operation, ‘final_result’, does not exist in the graph.”
What could be causing this?
windows 上出現的 output 檔案非 .pb 檔
我更改了retrain_model_classifier.py 裡 “./lables.txt”和“./output.pb”為windows內文件的路徑了
但會出現以下
File “retrain_model_classifier.py”, line 15
with tf.gfile.FastGFile(“\u202aC:\Users\leo860625\tfClassifier-master\image_
classification\output.pb”, ‘rb’) as f:
^
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in positio
n 12-13: truncated \UXXXXXXXX escape
請問要如何處理
Hi and thanks for sharing this. I have retrained a new model instance with a new set of images (5 classes). Any advice on how can be used to predict/make inference on my test set images ? i.e. is there a way for the script retrain_model_classifier.py to accept a whole directory of images ?
Also what modifications do we need to make to save the retrained model as .h5 at the end of the training?
Thank you in advance
Hi, you can use the script that I have provided to test the classification: https://github.com/akshaypai/tfClassifier/blob/master/retrain_model_classifier.py
this is not the only way but one of the ways you can do it. You might need to modify this script a bit to suit your need.
coming to storing it as a h5 file, you would need another script called Tensorflow to Keras . That script will help you convert the pb file to a h5 file.
Hi and a lot thanks for your sharing, i get some trouble when i try to run retrain_model_classifier.py
i run the script as this:
python .\retrain_model_classifier.py D:\yika\Desktop\temp\car.png
then i get the traceback below:
Traceback (most recent call last):
File “.\retrain_model_classifier.py”, line 18, in
graph_def.ParseFromString(f.read())
File “D:\DevEnv\Python\Python38\lib\site-packages\tensorflow\python\lib\io\file_io.py”, line 116, in read
self._preread_check()
File “D:\DevEnv\Python\Python38\lib\site-packages\tensorflow\python\lib\io\file_io.py”, line 78, in _preread_check
self._read_buf = _pywrap_file_io.BufferedInputStream(
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd5 in position 61: invalid continuation byte
it seems like a error in the retrain_new.py? i use it to retrain the mode,and get the files like output.graph.pb output_labels.txt.
but when i want to run retrain_model_classifier.py i got the traceback above.
Hi, this error indicates that there are issues while reading the data. This is expected in the windows system. So, it’s not able to decode the text which is unicode. you need to explicitly do that before passing the text to the PrseFromString method.
Hi,
yes, so you need to downgrade your TF version since this code was written with tf 1.10.x or tf 1.13.x in mind.
Hi. I got such error and i think that it connected with different version of TF
Traceback (most recent call last):
File “retrain.py”, line 967, in
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
File “/home/apteka/anaconda3/lib/python3.8/site-packages/tensorflow/python/platform/app.py”, line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File “/home/apteka/anaconda3/lib/python3.8/site-packages/absl/app.py”, line 300, in run
_run_main(main, args)
File “/home/apteka/anaconda3/lib/python3.8/site-packages/absl/app.py”, line 251, in _run_main
sys.exit(main(argv))
File “retrain.py”, line 741, in main
final_tensor) = add_final_training_ops(len(image_lists.keys()),
File “retrain.py”, line 640, in add_final_training_ops
bottleneck_input = tf.placeholder_with_default(
File “/home/apteka/anaconda3/lib/python3.8/site-packages/tensorflow/python/ops/array_ops.py”, line 3116, in placeholder_with_default
return gen_array_ops.placeholder_with_default(input, shape, name)
File “/home/apteka/anaconda3/lib/python3.8/site-packages/tensorflow/python/ops/gen_array_ops.py”, line 6930, in placeholder_with_default
return placeholder_with_default_eager_fallback(
File “/home/apteka/anaconda3/lib/python3.8/site-packages/tensorflow/python/ops/gen_array_ops.py”, line 6956, in placeholder_with_default_eager_fallback
_result = _execute.execute(b”PlaceholderWithDefault”, 1,
File “/home/apteka/anaconda3/lib/python3.8/site-packages/tensorflow/python/eager/execute.py”, line 75, in quick_execute
raise e
File “/home/apteka/anaconda3/lib/python3.8/site-packages/tensorflow/python/eager/execute.py”, line 59, in quick_execute
tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
TypeError: An op outside of the function building code is being passed
a “Graph” tensor. It is possible to have Graph tensors
leak out of the function building context by including a
tf.init_scope in your function building code.
For example, the following function will fail:
@tf.function
def has_init_scope():
my_constant = tf.constant(1.)
with tf.init_scope():
added = my_constant * 2
The graph tensor has name: pool_3/_reshape:0