With the growth in popularity of Artificial Intelligence, machine learning is a term one would hear very often. Right from big companies like Facebook and Google to small startups are talking about machine learning. Due to this, you might have had this question, “What is machine learning ?”. Let’s go through the details and some of the methods and jargons used in this field.
So, What is Machine Learning?
Machines having the capability to think and perform tasks without human intervention is termed Artificial Intelligence (AI). We are far from reaching this but we are trying to get there. Machine learning is just a small part or a small field of AI. It comprises of various algorithms to train a system to identify patterns.
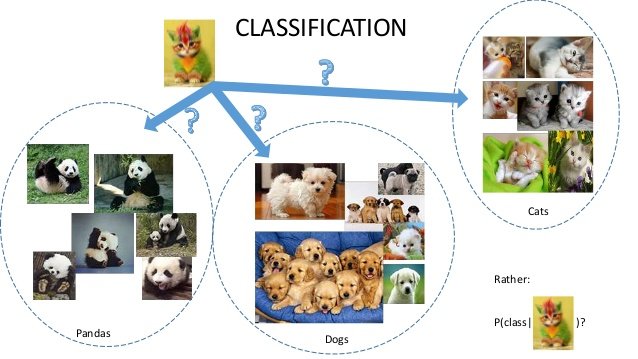
For example, we can give thousands of images of cats and dogs and ask the system to learn their differences. These algorithms then go through each of the images and collect various information like shape, color, and features. Once Identified, they then try to find patterns between similar images. Once it has identified some pattern, it can tell if a new image shown to it is a cat or a dog. This is called generalization and machine learning primarily focuses on this and nothing more.
There are people who use Machine learning synonymous with AI and that leads to a misunderstanding. The misunderstanding that we are making the system learn how to think and give us results when we throw problems at it. Though the name suggests learning, it isn’t quite so. We are just guiding the system to identify patterns required to perform some tasks. At the end of the day, it still wouldn’t know what a cat or a dog is. The only understanding it would have is “if some particular shapes are identified and some colors are found, etc, then there is a good chance that this might be a dog or a cat”. Now, this isn’t true learning if contexts aren’t identified.
What are the steps involved in machine learning?
Machine learning includes the following high-level steps.
1. Data Collection
The first step is to collect data. ML algorithms perform better with a larger amount of data. So, it is very important to make sure that a large amount of data is collected for the learning process. Once the data is collected, it has to be labeled correctly. Data collection is very important for other aspects such creating Reports and dashboards which can be used to understand the data in depth to get more insights.
2. Data Split
Once the data is collected, it has to be split into two parts: “Training Data” and “Testing Data“. The reason for the split is that we want to evaluate the accuracy of the learning. Accuracy can be determined by running the trained system on data it has never seen before and evaluating how many of them it has predicted or classified correctly.
The usual split is 70:30. This means that the collected data is randomly split into 2 parts such that the training data has 70% of the data collected. The test data has the remaining 30% collected.
3. Training the system
Training involves the running of the actual machine learning algorithm on the training data. The output of this is called a model which is capable of taking an input and performing the task it has learned. So the input to the model should be the same format as that of the training and testing data.
4. Testing the model
The model is then run on the test data and the results are recorded. These recorded data are then gathered and mathematical functions are applied to calculate the model’s accuracy. So, when someone says that ” This classifier model is 95% accurate”, it means that the classifier can correctly categorize the input 95% of the time.
5. Model storage and reuse
Once the model is tested and accepted, it needn’t be trained again. You can store the model and can be re-used to perfrom the task it has learned any number of times.
What can Machine Learning Achieve?
Machine Learning (ML)applications are plenty, however, here are some popular ones.
- Prediction – ML can be used for predicting the outcomes of the event. For example, we can train a system to predict the tomorrow’s weather. Another example is predicting the price of stocks 3 months from now.

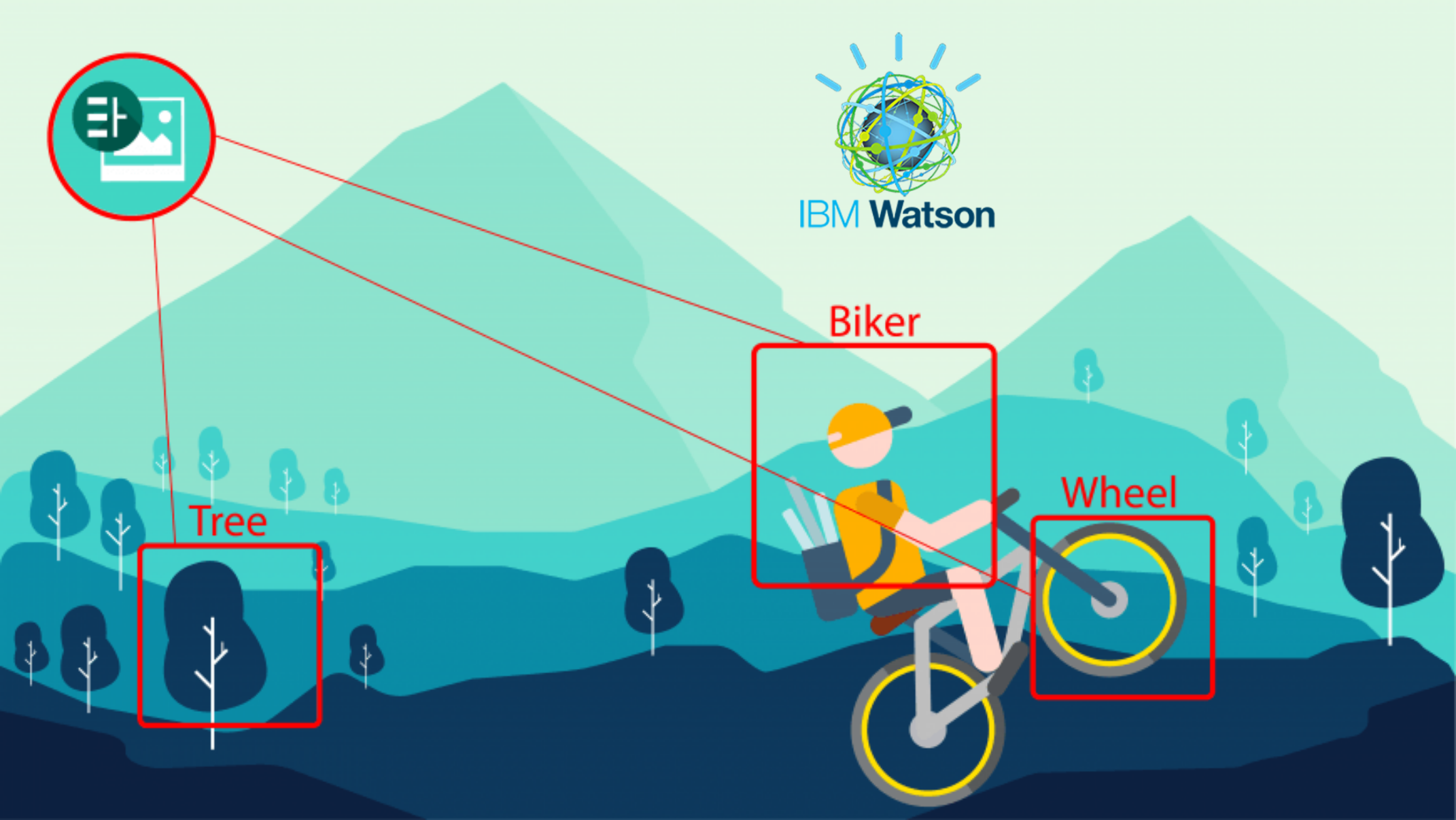
- Classification – Classification is the process of selecting the best match for any input among a given set of categories. Example, classifying if an email is spam or not spam. Another example is classifying if a given image is that of a bus, car, truck, plane, or train.

- Speech Recognition – This is the process of understanding what a person is saying. Siri or Cortana understand what you are saying and can respond back because of this.

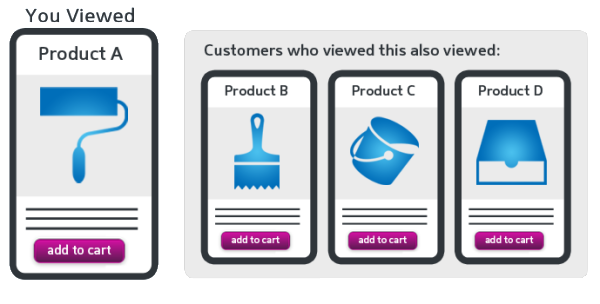
- Recommendations – Process of learning preferences of people over time and recommend new things which might not have been known to that person. Amazon recommends products to you, this is possible because of machine learning.



These are just some of them, there are tons of other applications.
There are a lot of algorithms which are used to achieve these. I am naming some of them here but their explanations are separate articles altogether. Support Vector Machines, Random Forest Classifiers, Neural Networks, Deep Neural Networks, Logistic Regression, Natural Language Processing are some of the very widely used algorithms to implement these applications.
Supervised and Unsupervised Machine Learning
Supervised and unsupervised learning needs to be addressed when we are answering the question “what is machine learning?”. Both of them are types of machine learning techniques.
Supervised learning is used when you know about the data you have beforehand. In this technique, you give the system a set of steps to perform on a finite set of outcomes. Consider the following example. You have collected student data from your college. You have the choice of categorizing the students with respect to their nationality, major, age, gender, etc. All this information is known beforehand. With this example, you can build a machine learning system that predicts the GPA of a student based on some of the known parameters.
Unsupervised Learning is used when the knowledge on data is missing or incomplete. This technique processes a given set of data and tries to separate them by finding differences. Clusters of data or data categorization are the output of this technique. For example, consider you have a bag full of colored boxes of varying sizes. You can provide this data to the machine and ask it to cluster them (segregate them). The machine might cluster these boxes based on size or color, we wouldn’t know as we do not supervise on how it clusters them. Once we have a cluster, we can then use that information to apply supervised learning and use it to perform a task like box classification.
With this, I hope I have answered the question ” What is machine learning ?”. These are just the basic concepts. Lot more content on machine learning with python will be published soon. Subscribe to the blog to make sure you don’t miss it.