What is Tensorflow Text Classification all About?
Text Classification is the task of assigning the right label to a given piece of text. This text can either be a phrase, a sentence or even a paragraph. Our aim would be to take in some text as input and attach or assign a label to it. Since we will be using Tensor Flow Is deep learning library, we can call this the Tensorflow text classification system. Seems simple doesn’t it? well, not so much.
This task involves training a neural network with lots of data indicating what a piece of text represents. I am sure you would have heard of the term “Sentiment Analysis“. Well, sentiment analysis a text classification task but it is restricted only to identify the sentiment of the person saying something. For example, the sentence, ” The food was amazing” has a positive sentiment. On the other hand, ” the movie was horrible” has a negative sentiment while the sentence “sun rises from the east” has a neutral sentiment.
For sentiment analysis, the labels are positive, negative and neutral most of the times. But, this is just one use of the text classification. If you are building other text-based applications like a chatbot, or a document parsing algorithm, you might want to know what a particular sentence belongs to. For example: ” Hello! how are you?” can have the label “Greeting” attached to it or the sentence ” It was a pleasure meeting you” can have the label “Farewell” attached to it.
What are you going to learn?
You could build a text classifier that classifies a given sentence to one of the many labels that the classifier is trained for. In this tutorial, we do just that. We will go through how you can build your own text-based classifier with loads of classes or labels.
The article Tensorflow text classification will be divided into multiple sections. First are the text pre-processing steps and creation and usage of the bag of words technique. Second is the training of the text classifier and finally the testing and using the classifier.
If you don’t know what Tensorflow is, then you can read this article What is Tensorflow first.
Some NLP terminologies before we begin
Natural Language Processing (NLP) is heavily being used in our text classification task. So, before we begin, I want to cover a few terms and concepts that we will be using. This will help you understand why a particular function or process is being called or at the very least clear any confusion you might have.
I) Stemming – Stemming is a process applied to a single word to derive its root. Many words that are being used in a sentence are often inflected or derived. To standardize our process, we would like to stem such words and end up with only root words. For example, a stemmer will convert the following words “walking”, “walked”, “walker” to its root word “walk“.
II) Tokenization – Tokens are basically words. This is a process of taking in a piece of text and find out all the unique words in the text. We would get a list of words in the text as the output of tokens.
For example, for the sentence “Python NLP is just going great” we have the token list [ “Python”, “NLP”, ïs”, “just”, “going”, “great”]. So, as you can see, tokenization involves breaking up the text into words.
III) Bag of Words – The Bag of Words model in Text Processing is the process of creating a unique list of words. This model is used as a tool for feature generation.
Eg: consider two sentences:
- Star Wars is better than Star Trek.
- Star Trek isn’t as good as Star Wars.
For the above two sentences, the bag of words will be: [“Star”, “Wars”, “Trek”, “better”, “good”, “isn’t”, “is”, “as”].
The position of each word in the list is hence fixed. Now, to construct a feature for classification from a sentence, we use a binary array ( an array where each element can either be 1 or 0).
For example, a new sentence, “Wars is good” will be represented as [0,1,0,0,1,0,1,0] . As you can see in the array, position 2 is set to 1 because the word in position 2 is “wars” in the bag of words which is also present in our example sentence. This same holds good for the other words “is” and “good” as well. You can read more about the Bag of Words model here.
NOTE:The code below is present to explain the procedure and it is not complete. You can find the full working code in my Github Repository ( Link is given at the end of the article).
Step 1: Data Preparation
Before we train a model that can classify a given text to a particular category, we have to first prepare the data. We can create a simple JSON file that will hold the required data for training.
Following is a sample file that I have created, that contains 5 categories. You can create how many ever categories that you want.
{
"time" : ["what time is it?", "how long has it been since we started?", "that's a long time ago", " I spoke to you last week", " I saw you yesterday"],
"sorry" : ["I'm extremely sorry", "did he apologize to you?", "I shouldn't have been rude"],
"greeting": ["Hello there!", "Hey man! How are you?", "hi"],
"farewell": ["It was a pleasure meeting you", "Good Bye.", "see you soon", "I gotta go now."],
"age": ["what's your age?", "How old are you?", "I'm a couple of years older than her", "You look aged!"]
}
In the above structure, we have a simple JSON with 5 categories ( time, sorry, greeting, farewell, and age). For each category, we have a set of sentences which we can use to train our model.
Given this data, we have to classify any given sentence into one of these 5 categories.
Step 2: Data Load and Pre-processing
# a table structure to hold the different punctuation used
tbl = dict.fromkeys(i for i in range(sys.maxunicode)
if unicodedata.category(chr(i)).startswith('P'))
# method to remove punctuations from sentences.
def remove_punctuation(text):
return text.translate(tbl)
# initialize the stemmer
stemmer = LancasterStemmer()
# variable to hold the Json data read from the file
data = None
# read the json file and load the training data
with open('data.json') as json_data:
data = json.load(json_data)
print(data)
# get a list of all categories to train for
categories = list(data.keys())
words = []
# a list of tuples with words in the sentence and category name
docs = []
for each_category in data.keys():
for each_sentence in data[each_category]:
# remove any punctuation from the sentence
each_sentence = remove_punctuation(each_sentence)
print(each_sentence)
# extract words from each sentence and append to the word list
w = nltk.word_tokenize(each_sentence)
print("tokenized words: ", w)
words.extend(w)
docs.append((w, each_category))
# stem and lower each word and remove duplicates
words = [stemmer.stem(w.lower()) for w in words]
words = sorted(list(set(words)))
print(words)
print(docs)
In the code above, we create multiple lists. One list “words” will hold all the unique stemmed words in all the sentences provided for training. Another list “categories” holds all the different categories.
the output of this step is the “docs” list which contains the words from each sentence and which category the sentence belongs. An example document is ([“whats”, “your”, “age”], “age”).
Step 3: Convert the data to Tensorflow Specification
From the previous step, we have documents but they are still in the text form. Tensorflow being a math library accepts the data in the numeric form. So, before we begin with the tensorflow text classification, we take the text form and apply the bag of words model to convert the sentence into a numeric binary array. We then store the labels/category, in the same way, that is a numeric binary array.
# create our training data
training = []
output = []
# create an empty array for our output
output_empty = [0] * len(categories)
for doc in docs:
# initialize our bag of words(bow) for each document in the list
bow = []
# list of tokenized words for the pattern
token_words = doc[0]
# stem each word
token_words = [stemmer.stem(word.lower()) for word in token_words]
# create our bag of words array
for w in words:
bow.append(1) if w in token_words else bow.append(0)
output_row = list(output_empty)
output_row[categories.index(doc[1])] = 1
# our training set will contain a the bag of words model and the output row that tells
# which catefory that bow belongs to.
training.append([bow, output_row])
# shuffle our features and turn into np.array as tensorflow takes in numpy array
random.shuffle(training)
training = np.array(training)
# trainX contains the Bag of words and train_y contains the label/ category
train_x = list(training[:, 0])
train_y = list(training[:, 1])
Step 4: Initiate Tensorflow Text Classification
With the documents in the right form, we can now begin the Tensorflow text classification. In this step, we build a simple Deep Neural Network and use that for training our model.
# reset underlying graph data
tf.reset_default_graph()
# Build neural network
net = tflearn.input_data(shape=[None, len(train_x[0])])
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, len(train_y[0]), activation='softmax')
net = tflearn.regression(net)
# Define model and setup tensorboard
model = tflearn.DNN(net, tensorboard_dir='tflearn_logs')
# Start training (apply gradient descent algorithm)
model.fit(train_x, train_y, n_epoch=1000, batch_size=8, show_metric=True)
model.save('model.tflearn')
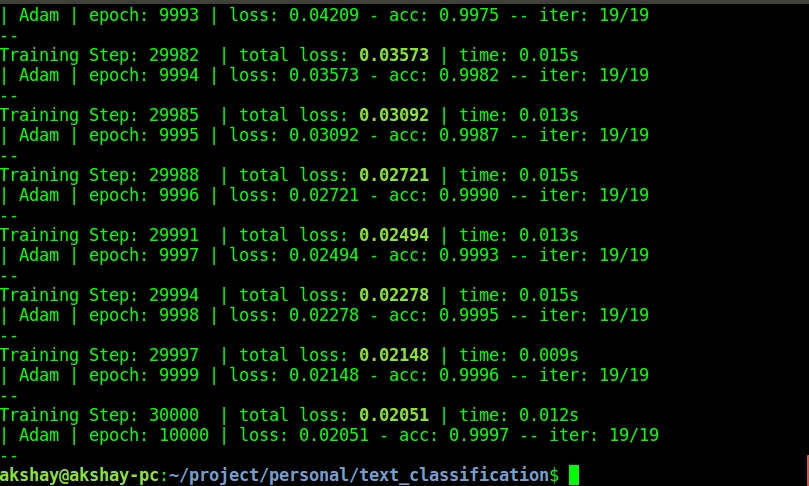
The code above runs for a 1000 epochs. I ran it for 10,000 epochs which had 30,000 steps and it took around 2 minuted to finish training.
I have the Nvidia Geforce 940MX GPU. the size of data and the type of GPU heavily determine the time taken for training.
I have attached a screenshot of the training below. I have achieved almost 100% training accuracy.
Step 5: Testing the Tensorflow Text Classification Model
We can now test the neural network text classification python model using the code below.
# let's test the model for a few sentences:
# the first two sentences are used for training, and the last two sentences are not present in the training data.
sent_1 = "what time is it?"
sent_2 = "I gotta go now"
sent_3 = "do you know the time now?"
sent_4 = "you must be a couple of years older then her!"
# a method that takes in a sentence and list of all words
# and returns the data in a form the can be fed to tensorflow
def get_tf_record(sentence):
global words
# tokenize the pattern
sentence_words = nltk.word_tokenize(sentence)
# stem each word
sentence_words = [stemmer.stem(word.lower()) for word in sentence_words]
# bag of words
bow = [0]*len(words)
for s in sentence_words:
for i, w in enumerate(words):
if w == s:
bow[i] = 1
return(np.array(bow))
# we can start to predict the results for each of the 4 sentences
print(categories[np.argmax(model.predict([get_tf_record(sent_1)]))])
print(categories[np.argmax(model.predict([get_tf_record(sent_2)]))])
print(categories[np.argmax(model.predict([get_tf_record(sent_3)]))])
print(categories[np.argmax(model.predict([get_tf_record(sent_4)]))])
Just with this training, the model was able to correctly classify all the sentences. There will definitely be a lot of sentences that might fail to be classified correctly.
This is only because the amount of data is less. with more and more data, you can be assured the model will be more confident.
Conclusion and Next Steps
This is how you can perform tensorflow text classification. You can use this approach and scale it to perform a lot of different classification. You can use it to build chatbots as well. If you are interested in learning the concepts here, following are the links to some of the best courses on the planet for deep learning and python. I have learned a lot from all of these courses and I would highly recommend this to anyone interested in machine learning, deep learning or learning advanced python in general.
Note: If you wish to enroll in any of the course below, click on the link you want to enroll to and please login or sign up to Udemy and you will get a 90% discount on the courses listed below.
- Complete Python 3 Bootcamp
 – For those of you who want to master Python programming.
– For those of you who want to master Python programming. - Python for Data Science and Machine Learning-For those who like to learn and master Machine learning.
- Deep Learning A-Z: Hands-On Artificial Neural NetworksDeep Learning A-Z: Hands-On Artificial Neural Networks – If you already know the basics of ML and want to learn deep learning, then this one is the best course for you.
This is just the beginning! You can use this concept as a base for advanced applications and scale it up.
You can find the complete working code for neural network text classification python in my Git Repository for tensorflow.




A guide to building a contextual Chatbot with tensorflow: https://chatbotsmagazine.com/contextual-chat-bots-with-tensorflow-4391749d0077
same task for text classification i am trying using R can u please suggest me the code for the same…Thanks in advance
Sorry, Rachit, I have no idea about R, so I won’t be able to help you.
Even I tried the same with python but showing number of errors , i am not that much comfortable with python , can u please suggest me for R
Hey, great tutorial but is there any possibility that you append the code with the accuracy of the model.
Hey, that is a possibility, I will try to add that sometime. If you have done that already, then please do raise a PR on github.
Hi….
Nice tutorial ,But i have one doubt how to print Accuracy against Predicted label not a model
For Example:
Sports,accuracy:0.87
Thanks
So, once you get the prediction list ( the list of probabilities for each class) you have to find the element with max value.
here’s the code to do it:
pred_result = model.predict([get_tf_record(“Hello, How are you”)])
max_val_index = np.argmax(model.predict([get_tf_record(sent_1)]))
accuracy_value = pred_result[max_val_index]
print(accuracy_value)
Thank you so much……sorry for delay response…….
Thanks for an excellent example.
This got me started with text classification on my text data.
In your sample the training and predict section is in the same python script…. How would you define and load that model for predictions in a separate standalone script?
You can save the model, using tflearn and then load it in another file. Once loaded, you can use the same methods as in this script to predict
Love this post! I’ve been trying to figure out how to do with with TF for some time.
Thanks! Glad it helped 🙂
Most examples for NLP in TensorFlow involve labels which are already given by the developer who creates and trains the TensorFlow model. I am beginner in this field and this seems to fall under the category of supervised learning. Is this correct?
Now I would like to have a training model with TensorFlow where I don’t give it any labels. It should classify sentences itself. There is a huge amount of data where labels are not clear. The hope is that TensorFlow finds clusters in the data which can be used for the labeling and classifying the sentences.
Yes, this most certainly falls into the supervised learning category. I haven’t worked on unsupervised learning with tensorflow yet. But i will surely update my blog when I do so.
thatns for useful article. Can you try to port the same to golang?
Sorry, I am not that good at golang, If you have done it, then please do raise a pull request.
i can test this as it is.
But i can’t load saved model using tensorflow not tflearn.
i understand that model is trained using tflearn and hence can be loaded in tflearn only.
Please try to port this completely to tensorflow.
Hi, sure, I will try to do this
Nice article. I am using this in a personal fun project. I noticed the following.
1. There are issues while restoring model in new code , avoiding to prepare data is cumbersome task.
2. tflearn github is almost unsupported for issues.
3. Even though model is restored with lot of modifications, its taking 3-4 seconds to run the program which is too slow.
4. predictions are different every time for same input (I loaded same saved model in each run without changing trained data) Is this because I added parameter restore=False on net = tflearn.fully_connected(net, 8, restore=False) to avoid shape mismatch exceptions on reloading the model?
These issues that you are facing is due to the version mismatch of tensorflow or some errors with the tensors that is being formed. I am using this extensively in many places and I can assure you that the results are stable and the performance is super fast. it in milli-seconds that I get results in.
I just cloned github code of this and retested. I dont see any issue with version issue in log?
Regarding this is slow : I have large model , with 224 labels and 1600 total sentences. tflearn restoring model with code in different program is not so easy. Even with few lines of code , we still need to have reference to `words`
I guess one can use different stemmer , I see stemmed words look weird. How about `nltk.stem.wordnetWordNetLemmatizer`
I just want to fix this issue of different predictions each time. I couldnt get same issue being mentioned anywhere in any blog either .
And tflearn does not have method to update the model with new data, we have call model.fit with updated data and them model.save again which will retrain the whole model and takes a lot of time.
You can certainly try the nltk.stem.wordnetWordNetLemmatizer . Even with that large dataset, I don’t think it should be an issue for the program to either run slowly or not to be stable. I will try to look at this when I shave some time.
I searched a lot and found that it is expected behavior of Neural nets to output different predictions for same input when we have randomness in place and dropouts not added.
[Stackoverflow answer](https://stackoverflow.com/questions/44994533/neural-network-gives-different-output-for-same-input)
Oh that’s awesome!
“Output predictions vary every time with the mentioned code as well without any changes. I think this is weird.
Error importing tensorflow. Unless you are using bazel,
you should not try to import tensorflow from its source directory;
please exit the tensorflow source tree, and relaunch your python interpreter
from there.
Hi, that’s a great tutorial. However, do you mind to provide more strings in the data.json? I realized that when I add more string to perform the machine learning, the accuracy went downhills.
Could you send me the json that you are using? I feel it’s not due to more number of strings that the accuracy has gone down. I feel it might be due to the way in which you have categorized the data. Sometimes, categorization does not allow the neural network to correctly classify the input data.
Hello,
I downloaded source code from your Github repo. But When I running “classify_text.py” and then it gives below error message. How can I fix it ?
TypeError: category() argument 1 must be unicode, not str
hi John, I am not getting this error, but to solve it, you will have to convert your string to a Unicode string. here is on way to do it: str(text,’utf-8′) . this encodes the string to form a Unicode-string. Here is more details: https://stackoverflow.com/questions/6812031/how-to-make-unicode-string-with-python3
Hello,
thanks for the great tutorial. I combined it with your chatbot tutorial and everything works but the prediction takes very long (20-30 seconds). I have trained the model with 3 categories with about 5000 words each category). The pickle file has 104MB. Is there a way to make the prediction faster?
Thank you for posting
Thanks.. Nice Tutorial.
Hi, is it possible to share full code with library imports and stuff? Having bunch of errors trying to achieve result. much appreciated.
Hi, at the end of the article, I have shared the link to the GitHub project from which you will get all the code. Have you checked that? Let me know if you tried it and it didn’t work.
Thank you very much.
Thank You very very much you’ve helped me a lot. I faced some errors regarding missing modules but I fixed them and now it works well. I really appreciate people helping others.
I have a question, how can I know the supported languages in the preprocessing methods? (specially Arabic Language) and thanks again
Hello Nuha,
I’m glad to know that this has helped you. With regards to supported languages, I haven’t tried running it with languages other than English. But if you observe, the processing uses the Unicode notations which means it can support any given language that we know (Arabic included)
I hope that you can get it up and running for Arabic 🙂
Thank you for your good scripts
I run this script with excel file as input data and it works finely
I want to load my model after i save it.
how can i do it?
thank you for your reply
in the code that I have provided, you would have seen that I have saved the model, using model.save().
To load the model, you need to use the model.load() method.
Here is an example: https://github.com/tflearn/tflearn/blob/master/examples/basics/weights_persistence.py
Hi akshay.
Thanks for the Scripts.The Scripts working fine as i expect .But my doubt is how to predict the value from saved model .
For Example.my expected scripts will be……
model.Save(‘C:\document\model\’)
model.load(‘C:\document\model\’)
sent_1 = “what time is it?”
sent_2 = “I gotta go now”
sent_3 = “do you know the time now?”
sent_4 = “you must be a couple of years older then her!”
# a method that takes in a sentence and list of all words
# and returns the data in a form the can be fed to tensorflow
def get_tf_record(sentence):
global words
# tokenize the pattern
sentence_words = nltk.word_tokenize(sentence)
# stem each word
sentence_words = [stemmer.stem(word.lower()) for word in sentence_words]
# bag of words
bow = [0]*len(words)
for s in sentence_words:
for i, w in enumerate(words):
if w == s:
bow[i] = 1
return(np.array(bow))
# we can start to predict the results for each of the 4 sentences
print(categories[np.argmax(model.predict([get_tf_record(sent_1)]))])
print(categories[np.argmax(model.predict([get_tf_record(sent_2)]))])
print(categories[np.argmax(model.predict([get_tf_record(sent_3)]))])
print(categories[np.argmax(model.predict([get_tf_record(sent_4)]))]
Note:My requirement is i need to predict value from saved model not again load the training data …
Thanks…
Hi Udya,
I didn’t understand you completely. What you have shared above does not load the training data.
once you load the training model, you can use that yo send in any sentence you want ( after pre-processing) and get the index of the class ( category) which got the highest score.
That index of the class will be a number like 0 or 1 or 2, etc, . So, we will have a labels ( or categories) where it will store mapping between index to human readable class name. So, 0 will be converted to “greeting” , 1 will be converted to “sorry” and so on.
Hi akshay thanks for ur reply….
Yes ur right I have created and saved new mode in specific path and I loaded the model from path by passing input string it working fine.but my requirement is I have saved new model why I need to run full source code (training Json data) instead of prediction code only.
Note :spacy entity recognition.
Thanks.
Oh okay, i understand what your trying to achieve. The script that you have sent earlier as example is almost correct.
Your script will start with model.load() and you should load it from what you have stored it. Once that is done, you can create a method which accepts an image file or and image file path and preprocess it . Finally it will call the predict method.
So from what you have sent above, you can make some changes and you will have what you want.
Hi akshay, can we use word embedding using word2vec instead of bag of words? Because if there is large corpus than there will be huge number of zeros for a sentence.
Hi Amit,
WordToVec is designed to convert a word to a vector or a phrase to a vector. When using TF bag of words model, the same is happening internally.
Though I haven’t used word-to-vec, I know that the existing approach is quote scalable.
hi akshay thank u for script it helped me lot ..
i want to see these predicted probabilities can u do that step for me ,
model.predict([get_tf_record(sent_1)])
i need to see these probabilities for all predicted data and in that i will see it’s taking highest probability is printing cab u do …it will help me lot. thanks
So, you’re looking to get all the probability instead of just the highest right?
for x in categories_Process[np.argmax(model_CP_Process.predict([get_tf_record_CP_ProcessDescription(values[1])])*100)]:
print (x)
instead of argmax i want read all predicted values , i hope u understand
okay, so argmax here is giving you the index of the category that has got the highest probability. If you want all the probabilities, then all you gotta do is remove the argmax. So, instead of printing it out like “print(categories[np.argmax(model.predict([get_tf_record(sent_1)]))])” , you will have to just use “print(model.predict([get_tf_record(sent_1)])))” and that will return you the list of probabilities as a numpy array.
Hello!
I’m trying to run this on python 2.7 but I’m getting this error on line 14: TypeError: must be unicode, not str
That’s a typical Unicode error when the string is not encoded.
To fix it you have to encode it.
On line 14, see where the string variable is present and then do a .encode(“utf-8”) it should work then
Hi! Great tutorial. How can I prevent the script for training every time I run it? Can I comment some lines like line 13 and 14 so the script can use already saved model?
Hi!
How to create .pb file using the generated model.
from what I recollect, the graph will be stored as .pb file by default. if not, then how is it currently storing the model for you?
how to show accuracy here
As you can see the image while training, the accuracy at the end of each epoch is printed.
However, if you need the accuracy at a later point in time, then you need a test dataset and you can find the explanation for that here:https://stackoverflow.com/questions/48392776/finding-accuracy-of-tensorflow-model
How can we use this model in a browser???? Please reply I urgently need this to be done…
So, for the browser, you need to use something called Tensorflow JS, and have the model converted to the format that Tensorflow.js supports. You can find more information on it here: https://www.tensorflow.org/js
Can you please share the code for saving as well as loading?
Thank you for this tutorial, on question though: I could not figure out whether you are using RNN or CNN models and why, could you help me with that?
It’s neither a CNN or an RNN. It’s just a simple DNN which was more than sufficient to do the classification